Përshëndetje për të gjithë lexuesit e blog!
Unë mendoj se ata që shpesh punojnë në kompjuter (nuk luajnë, përkatësisht punë), u është dashur të merren me njohjen e tekstit. Epo, për shembull, keni skanuar një fragment nga një libër dhe tani duhet ta futni këtë pjesë në dokumentin tuaj. Por dokumenti i skanuar është një fotografi, dhe ne kemi nevojë për tekst - për këtë kemi nevojë për programe speciale dhe shërbime online për njohjen e tekstit nga fotot.
Në lidhje me programet e njohjes, unë kam shkruar tashmë në postimet e mëparshme:
- skanimi dhe njohja e tekstit në FineReader (program me pagesë);
- Puna në FineReader analoge - CuneiForm (program falas).
Në të njëjtin artikull, unë do të doja të ndalem në shërbimet në internet për njohjen e tekstit. Në fund të fundit, nëse keni nevojë të merrni një tekst të shpejtë me 1-2 fotografi - nuk ka kuptim të shqetësoni me instalimin e programeve të ndryshme ...
E rëndësishme! Cilësia e njohjes (numri i gabimeve, lexueshmëria, etj.) Varet shumë nga cilësia origjinale e figurës. Prandaj, kur skanoni (fotografoni, etj), zgjidhni cilësinë sa më të lartë që të jetë e mundur. Në shumicën e rasteve, një cilësi prej 300-400 dpi do të jetë e mjaftueshme (dpi është një parametër që karakterizon cilësinë e figurës. Në cilësimet e pothuajse të gjithë skanuesve, zakonisht tregohet ky parametër).
Shërbime Online
Për të treguar se si funksionojnë shërbimet, mora një pamje nga një prej artikujve të mi. Kjo pamje do të ngarkohet në të gjitha shërbimet, përshkrimi i të cilave është paraqitur më poshtë.
1) //www.ocrconvert.com/

Më pëlqen shumë ky shërbim për shkak të thjeshtësisë së tij. Faqja, megjithëse është anglisht, por funksionon mirë me gjuhën ruse. Nuk ka nevojë të regjistroheni. Për të filluar njohjen, duhet të bëni 3 veprime:
- ngarkoni imazhin tuaj;
- zgjidhni gjuhën e tekstit që është në figurë;
- shtypni butonin e fillimit të njohjes.
Mbështetje për formatet: PDF, GIF, BMP, JPEG.
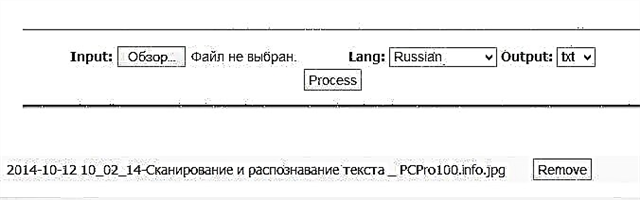
Rezultati është paraqitur më poshtë në figurë. Duhet të them, teksti është mjaft i njohur. Përveç kësaj, shumë shpejt - prita fjalë për fjalë 5-10 sekonda.

2) //www.i2ocr.com/
Ky shërbim funksionon në mënyrë të ngjashme me sa më sipër. Këtu gjithashtu duhet të shkarkoni skedarin, të zgjidhni gjuhën e njohjes dhe të klikoni butonin e tekstit ekstrakt. Shërbimi funksionon shumë shpejt: 5-6 sekonda. një faqe.
Formatet e mbështetura: TIF, JPEG, PNG, BMP, GIF, PBM, PGM, PPM.

Rezultati i këtij shërbimi në internet është shumë më i përshtatshëm: menjëherë shihni dy dritare - në të parën, rezultatin e njohjes, në të dytën - imazhin origjinal. Prandaj, është mjaft e lehtë për të bërë redaktimet ndërsa redaktoni. Nga rruga, regjistrimi në shërbim gjithashtu nuk është i nevojshëm.

3) //www.newocr.com/

Ky shërbim është unik në disa mënyra. Së pari, ai mbështet formatin "newfangled" DJVU (nga rruga, një listë të plotë të formateve: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu). Së dyti, mbështet zgjedhjen e zonave të tekstit në figurë. Kjo është shumë e dobishme kur nuk keni vetëm fusha teksti në figurë, por edhe zona grafike që nuk keni nevojë t’i njihni.
Cilësia e njohjes është mbi mesataren, nuk ka nevojë të regjistrohet.

4) //www.free-ocr.com/

Një shërbim shumë i thjeshtë për njohje: ngarkoni një imazh, specifikoni gjuhën, shkruani captcha (nga rruga, shërbimi i vetëm në këtë artikull ku ta bëni këtë), dhe shtypni butonin për të përkthyer imazhin në tekst. Në të vërtetë gjithçka!
Formatet e mbështetura: PDF, JPG, GIF, TIFF, BMP.

Rezultati i njohjes është mesatar. Ka gabime, por jo shumë. Sidoqoftë, nëse cilësia e pamjes origjinale të ekranit do të ishte më e lartë, do të kishte një renditje më të madhe gabimesh.

PS
Kjo është gjithçka për sot. Nëse dini shërbime më interesante për njohjen e tekstit - ndajini në komente, do t'ju jem mirënjohës. Një kusht: është e dëshirueshme që të mos keni nevojë të regjistroheni dhe shërbimi është falas.
Të gjitha më të mirat!